什么是 Spring Data JPA?
Spring Data JPA 是 Spring Data 项目的一部分,它提供了一种简化的数据访问方式,用于与关系型数据库进行交互。它基于 Java Persistence API(JPA) 标准,并提供了一套简洁的 API 和注解,使开发人员能够通过简单的 Java 对象来表示数据库表,并通过自动生成的 SQL 语句执行常见的 CRUD 操作。Spring Data JPA 通过封装 JPA 的复杂性,简化了数据访问层的开发工作,使开发人员能够更专注于业务逻辑的实现。它还提供了丰富的查询方法的定义、分页和排序支持、事务管理等功能,使开发人员能够更方便地进行数据访问和操作。
Spring Data JPA 的优势
- 简化数据库操作:通过提供丰富的接口和抽象,Spring Data JPA 减少了样板代码的编写。
- 强大的查询功能:支持基于方法名的查询、JPQL、SQL 以及 Specifications。
- 集成 Spring 生态系统:与 Spring Boot 无缝集成,提供了事务管理、集成测试等特性。
- 灵活性和可扩展性:允许自定义 Repository 方法,以实现复杂的数据库操作。
Spring Boot 中集成 Spring Data JPA
在 Spring Boot 应用程序中集成 Spring Data JPA 非常简单。以下是一些基本步骤:
步骤 1:添加依赖
在 pom.xml 文件中添加 Spring Data JPA 和数据库驱动的依赖。
1 | <dependencies> |
步骤 2:配置数据源
在 application.yml 文件中配置数据库连接信息。
1 | spring: |
步骤 3:创建实体类
定义一个实体类,使用 JPA 注解映射到数据库表。
1 |
|
步骤 4:创建 Repository 接口
创建一个继承 JpaRepository 的接口,用于定义数据访问操作。
1 | public interface BookRepository extends JpaRepository<Book, Integer> { |
步骤 5:使用 Repository
在控制层中注入 BookRepository 并使用它来执行数据库操作。
1 |
|
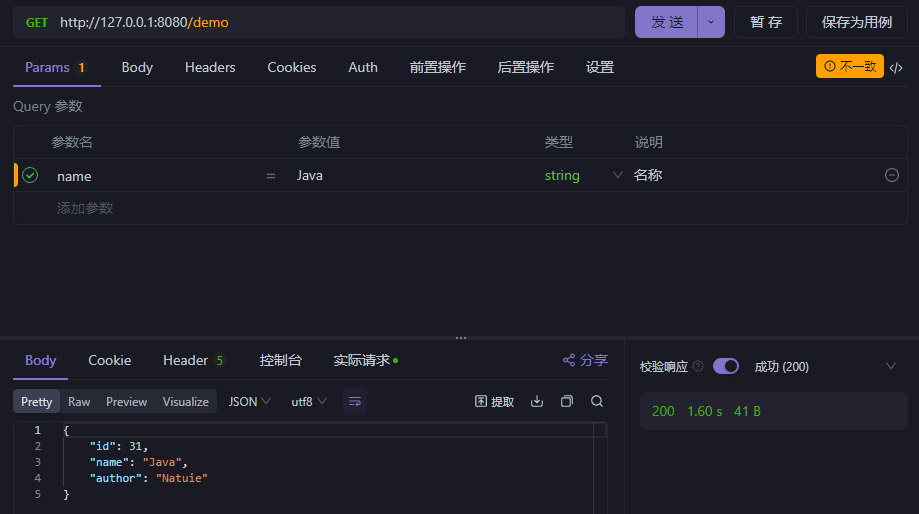
运行项目,请求/demo这个api,可以看到返回了这本书的信息。
JPA基本注解
| 注解 | 解释 |
|---|---|
@Entity |
声明类为实体。 |
@Table |
声明实体类对应的表名。如果省略,默认表名将与实体类名相同。 |
@Column |
指定实体类属性映射到数据库表的列名。如果省略,默认列名将与属性名相同。 |
@Id |
指定实体类的唯一标识符,通常为主键。 |
@GeneratedValue |
指定主键的生成策略,如自动增长、序列、UUID等。 |
@Transient |
表示该属性并非一个数据库表的字段的映射,ORM框架将忽略该属性。 |
@ColumnResult |
用于指定查询结果中的列名。 |
@Embedded |
用于注释属性,表示该属性的类是嵌入类。 |
@Embeddable |
用于注释Java类,表示该类是嵌入类。 |
@Basic |
指定实体属性的加载方式,如是否懒加载。 |
@SequenceGenerator |
指定序列生成器的策略,用于生成主键。 |
@TableGenerator |
在数据库中生成一张表来管理主键生成策略。 |
@AccessType |
设置访问类型,决定是否通过字段或通过getter/setter方法访问实体属性。 |
@UniqueConstraint |
指定实体类属性组合的唯一约束。 |
@NamedQueries |
指定命名查询的列表,用于在JPQL中定义命名查询。 |
@NamedQuery |
指定使用静态名称的查询,通常在接口中使用。 |
基本用法
插入
要插入一个新的书籍,您可以使用 save 方法。
1 | bookRepository.save(new Book("学习Spring Boot", "学习者")); |
查询
在 Spring Data JPA 中,查询关键字映射是通过方法名到查询逻辑的映射。这些映射是基于约定的,也就是说,Spring Data JPA 会根据接口方法的名字来推断要执行的查询。以下是一些常见的查询关键字映射:
基本查询
findBy<FieldName>: 查找具有指定字段值的实体。readBy<FieldName>: 类似于findBy,但通常用于只读操作。getBy<FieldName>: 类似于findBy,但通常用于获取单个实体。queryBy<FieldName>: 类似于findBy,但提供更灵活的查询构造。streamBy<FieldName>: 流式地查找具有指定字段值的实体。
多个字段
findBy<FieldName1>And<FieldName2>: 查找具有指定字段组合值的实体。readBy<FieldName1>And<FieldName2>: 类似于findBy,但通常用于只读操作。getBy<FieldName1>And<FieldName2>: 类似于findBy,但通常用于获取单个实体。queryBy<FieldName1>And<FieldName2>: 类似于findBy,但提供更灵活的查询构造。streamBy<FieldName1>And<FieldName2>: 流式地查找具有指定字段组合值的实体。
字段比较
findBy<FieldName>Eq<Value>: 查找字段等于指定值的实体。readBy<FieldName>Eq<Value>: 类似于findBy,但通常用于只读操作。getBy<FieldName>Eq<Value>: 类似于findBy,但通常用于获取单个实体。queryBy<FieldName>Eq<Value>: 类似于findBy,但提供更灵活的查询构造。streamBy<FieldName>Eq<Value>: 流式地查找字段等于指定值的实体。
字段不等
findBy<FieldName>NotEq<Value>: 查找字段不等于指定值的实体。readBy<FieldName>NotEq<Value>: 类似于findBy,但通常用于只读操作。getBy<FieldName>NotEq<Value>: 类似于findBy,但通常用于获取单个实体。queryBy<FieldName>NotEq<Value>: 类似于findBy,但提供更灵活的查询构造。streamBy<FieldName>NotEq<Value>: 流式地查找字段不等于指定值的实体。
字段包含
findBy<FieldName>Containing<Value>: 查找字段包含指定值的实体。readBy<FieldName>Containing<Value>: 类似于findBy,但通常用于只读操作。getBy<FieldName>Containing<Value>: 类似于findBy,但通常用于获取单个实体。queryBy<FieldName>Containing<Value>: 类似于findBy,但提供更灵活的查询构造。streamBy<FieldName>Containing<Value>: 流式地查找字段包含指定值的实体。
字段不包含
findBy<FieldName>NotContaining<Value>: 查找字段不包含指定值的实体。readBy<FieldName>NotContaining<Value>: 类似于findBy,但通常用于只读操作。getBy<FieldName>NotContaining<Value>: 类似于findBy,但通常用于获取单个实体。queryBy<FieldName>NotContaining<Value>: 类似于findBy,但提供更灵活的查询构造。streamBy<FieldName>NotContaining<Value>: 流式地查找字段不包含指定值的实体。
字段开始于
findBy<FieldName>StartingWith<Value>: 查找字段以指定值开始的实体。readBy<FieldName>StartingWith<Value>: 类似于findBy,但通常用于只读。
下面给出示例:
1 | public interface BookRepository extends JpaRepository<Book,Integer> { |
这个示例中,我们看到,我们只是通过方法名来定义要做什么,并无需手写具体实现方法,这极大的有利于我们快速开发。findByName方法通过name来获取书籍,如果存在同名,需要返回List
下面根据书名来查找书籍,通过调用上面写的findByName 方法来实现。
1 | bookRepository.findByName(name); |
查找所有书籍。
1 | bookRepository.findAll(); |
更新
要更新一个书籍,也使用 save 方法,首先查找书籍再更新。
1 | Book book = bookRepository.findByName(name); |
删除
要删除所有指定名称的书籍,您可以调用 deleteAllByName 方法。删除和查找的方法名命名是一样的,它也具有这样的功能,区别在于它前缀是delete。
1 | bookRepository.deleteAllByName(name); |
分页
如果您想要获取分页的书籍列表,您可以使用 Pageable 参数。这里的PageRequest.of有2个参数,pageNumber:页数,pageSize:每页多少页。
1 | bookRepository.findAll(PageRequest.of(1, 2)).getContent(); |
排序
方法1: 基于特殊参数的排序
建立分页对象:
1 | Pageable pageable = new PageRequest(pageNum, pageSize); |
在Repository中定义相应的方法:
1 | Page<Book> findByOrderByNameAsc(Pageable pageable); // 按照名字来升序,Desc:降序,Asc:升序 |
这里使用默认的字段拼接形成的方法名,从而自动解析形成对应的方法,具体见前面。
方法2: 基于自定义的@Query进行排序
建立分页对象:
1 | Pageable pageable = new PageRequest(pageNum, pageSize); |
在Repository中定义相应的语句:
1 | @Query("select b from Book b ORDER BY b.name ASC") |
方法3: 基于Pageable中的Sort字段
Pageable对象的声明:
1 | Sort sort = new Sort(Direction.ASC, "name"); |
这里将Sort字段作为参数创建了Pageable对象。
在Repository无需声明任何新的方法,直接使用JpaRepository中继承而来的findAll(Pageable pageable)方法即可。
调用具体Repository中的方法如下:
1 | Page<Book> book = bookRepository.findAll(pageable); |
以上只提供的一些简单的用法,更多文档可参考Spring Data JPA 中文文档 (springdoc.cn)
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




